A reproducible analysis of college basketball data with R
Author
ProPlotFits
Published
February 19, 2026
Introduction
For context, please see Part 1 here.
What We’re Looking For
If the goal is to use data to bet responsible AND share our results in reproducible manner, we need to isolate the data that helps us develop a model that predicts winners in potential match-ups.
Dean Oliver narrowed the most important analytics of college basketball down to Four Factors:
Shooting Efficiency - More baskets and fewer misses
Turnovers - Number of times losing a possession
Rebounds - Number of times gaining a possession
Free Throws - Free points
Additionally, there are efficiency ratings - points scored and allowed per 100 possessions - which help adjust for pace.
When we talk about using machine learning to help us predict the outcome of match-ups, what we are actually doing is identifying features of a phenomena that could potentially assist us in determining outcomes. That is incredibly boiled down, but when we develop these predictive models, the models themselves let the analysts know what features are driving most of the explanation.
How You Can Use This
We are going to take a look at a hypothetical match-up between the Kansas Jayhawks and the Miami RedHawks. There is a slight chance they could in fact end up playing each other in the tournament IF they are in the same region. There is likely no chance they both make it to the Final Four.
This exact workflow works for any team in Division I basketball.
The steps:
Load schedule and box scores with hoopR
Calculate four factors using the formulas above
Calculate efficiency ratings
Visualize trends with ggplot2
Compare head-to-head results
Step 1: Retrieve official ESPN data
Loading data using the help of an R package named hoopR. You can learn more about its documentation, but it’s basically an API call to EPSN for live college basketball data.
I am using other libraries of course, but we don’t have time to talk about them!
Code
library(ggplot2)library(dplyr)
Attaching package: 'dplyr'
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
Code
library(hoopR)
Warning: package 'hoopR' was built under R version 4.5.2
Code
library(janitor)
Warning: package 'janitor' was built under R version 4.5.2
Attaching package: 'janitor'
The following objects are masked from 'package:stats':
chisq.test, fisher.test
Code
schedule <-load_mbb_schedule(seasons =2026) |>clean_names()box_scores <-load_mbb_team_box(seasons =2026) |>clean_names()# Filter to just Kansas & Miamihawks <- box_scores |>filter(team_display_name %in%c("Kansas Jayhawks", "Miami (OH) RedHawks"))# Quick look at what we havestr(hawks[1:2,])
I’ve taken the first two rows of our hawks data frame, which was filtered from the 2026 box score data stored in box_scores and told R to give me its structure. We have 59 columns; R lists them in order of appearance in the matrix, defines the type of data we are dealing with, shows us how many observations and then gives us a preview of said observations.
We can see that these are the most recent games for both teams.
Step 2: Calculate the Four Factors
Now let’s calculate Oliver’s Four Factors for both teams.
Code
four_factors <- hawks |>mutate(# Effective Field Goal % (weights three-pointers appropriately)efg_pct = (field_goals_made +0.5* three_point_field_goals_made) / field_goals_attempted,# Turnover % (turnovers per 100 possessions)tov_pct = turnovers / (field_goals_attempted +0.44* free_throws_attempted + turnovers),# Offensive Rebound % (offensive rebounds captured)orb_pct = offensive_rebounds / (offensive_rebounds + defensive_rebounds),# Free Throw Rate (free throw attempts per field goal attempt)ft_rate = free_throws_made / field_goals_attempted ) |>select(team_display_name, game_date, team_score, opponent_team_score, efg_pct, tov_pct, orb_pct, ft_rate)# Show the first few gameshead(four_factors, 10) |> knitr::kable()
Warning: package 'kableExtra' was built under R version 4.5.2
Attaching package: 'kableExtra'
The following object is masked from 'package:dplyr':
group_rows
Code
season_averages |> knitr::kable(digits =3,col.names =c("Team", "Games", "eFG%", "TOV%", "ORB%", "FTR"),caption ="Season Averages: Four Factors",format ="html",escape =FALSE ) |>kable_styling(bootstrap_options =c("striped", "hover")) |># Highlight max eFG% (higher is better)column_spec(3, background =ifelse(season_averages$avg_efg ==max(season_averages$avg_efg),"#d4edda", "white")) |># Highlight min TOV% (lower is better) column_spec(4,background =ifelse(season_averages$avg_tov ==min(season_averages$avg_tov),"#d4edda", "white")) |># Highlight max ORB% (higher is better)column_spec(5,background =ifelse(season_averages$avg_orb ==max(season_averages$avg_orb),"#d4edda", "white")) |># Highlight max FTR (higher is better)column_spec(6,background =ifelse(season_averages$avg_ftr ==max(season_averages$avg_ftr),"#d4edda", "white"))
Season Averages: Four Factors
Team
Games
eFG%
TOV%
ORB%
FTR
Kansas Jayhawks
26
0.535
0.136
0.244
0.259
Miami (OH) RedHawks
26
0.621
0.133
0.225
0.312
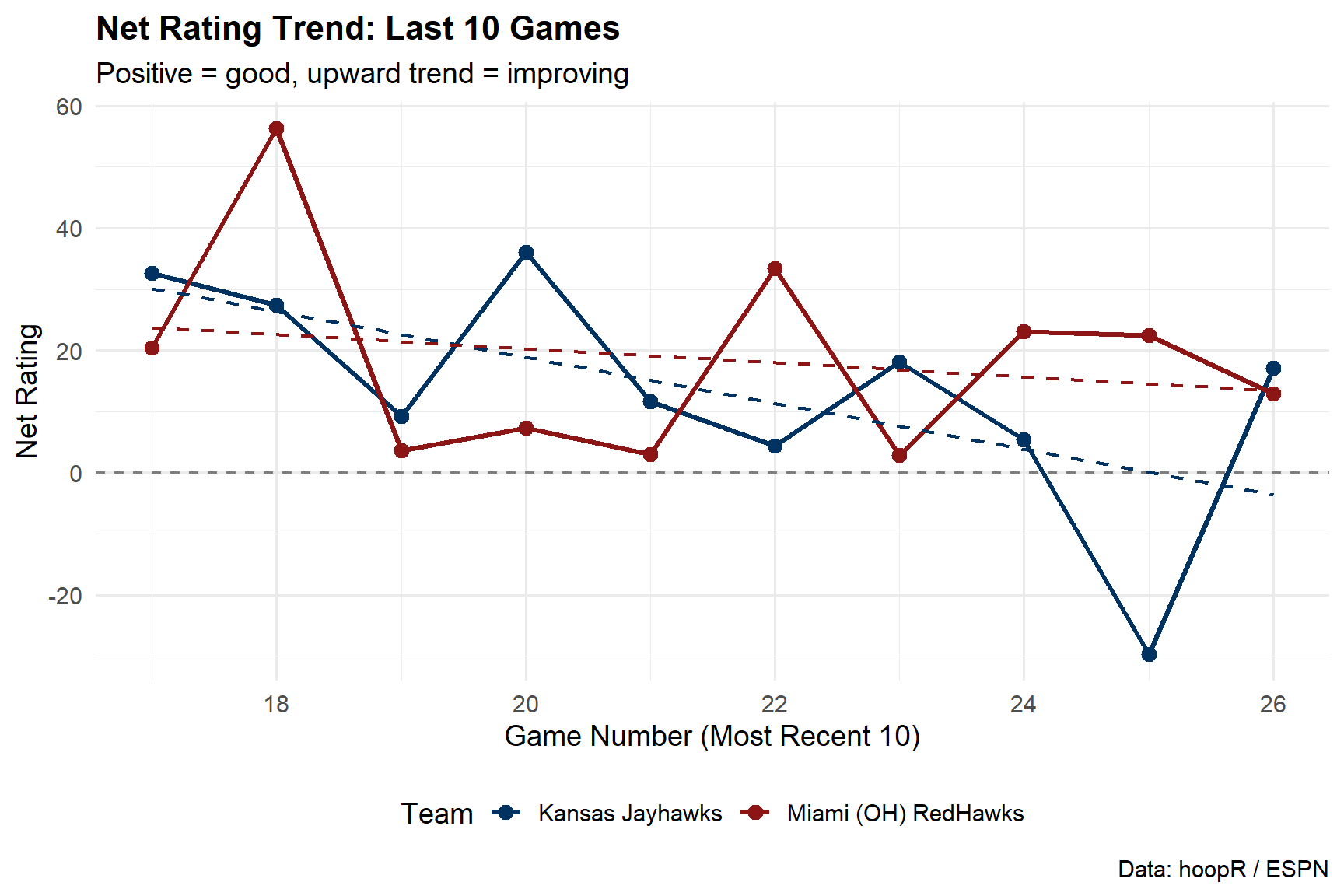
Would you look at that. Miami’s offense outperforms Kansas…if you completely ignore the quality of opponents Miami has played vs Kansas. The Big 12 has Houston, Arizona, Iowa State, Texas Tech and BYU in the AP Top 25 along with Kansas. Miami’s best win as a 3-point home win over Akron.
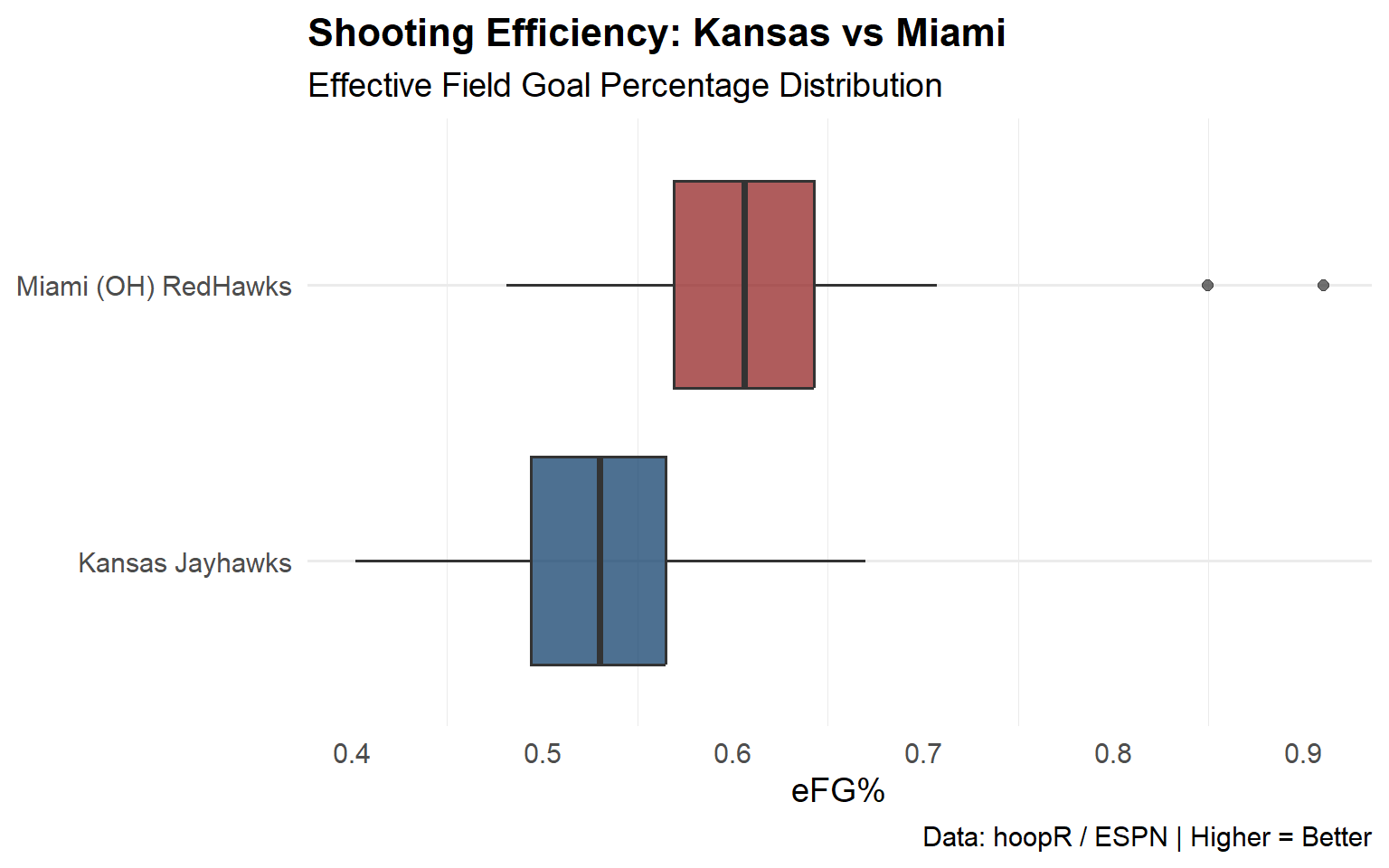
Step 4: Visualize Shooting Efficiency
Let’s look at how consistent each team is at making shots.
Miami appears to be in a more stable position than Kansas. As a unit, Miami definitely seems more consistent.
Conclusion
This workflow can be reproduced for any of the 360+ Division-1 Mens’ Basketball Teams. In Part 3 of this series, we’ll walk through how to build machine learning models to incorporate all of this data and predict who would win in a potential match-up between Kansas and Miami, the margin of victory and the total points scored.
Want to see more analyses like this? Subscribe to our Telegram for daily picks and breakdowns.